Why benchmarks fail in the real world
We started with a simple question: how do you create a fair way to evaluate AI systems?
At SAI, we built a benchmarking platform that provides a level playing field for testing policies against complex environments. The idea was to standardize evaluation — same tasks, same environments, same metrics. Teams could test their agents, compare results, and measure progress objectively.
But as we worked with more teams deploying systems in the real world, we noticed something. The agents that performed well on benchmarks often struggled in deployment. A model that excelled in evaluation would fail when:
- The camera angle changed
- Instructions were phrased differently
- The lighting wasn’t perfect
- Hardware ran slower than expected
The gap wasn’t about whether systems could do the task, but whether they could keep working when things weren’t ideal.
Benchmarks measure performance under standardized conditions. But real systems don’t operate in standardized conditions. They operate in warehouses with varying lighting. Factories with different equipment. Homes where every environment is unique.
The problem: We were measuring the wrong thing.
We were asking “how well does this system perform?” when we should have been asking “where does this system break, and why?”
Case Study: Humanoid Soccer Competition
In November 2025, we launched the Booster Soccer Showdown, a competition challenging participants to develop general policies that could control a simulated humanoid robot to kick a soccer ball toward a goal across different environments. Users submitted their trained models, which were then evaluated across hundreds of randomized scenarios varying ball positions, distances, and environmental conditions.
One particular submission caught our attention. The policy succeeded in passing the ball to the target 28% of the time, but because the distribution was bimodal, we knew that the aggregate metric wasn’t telling the whole story.
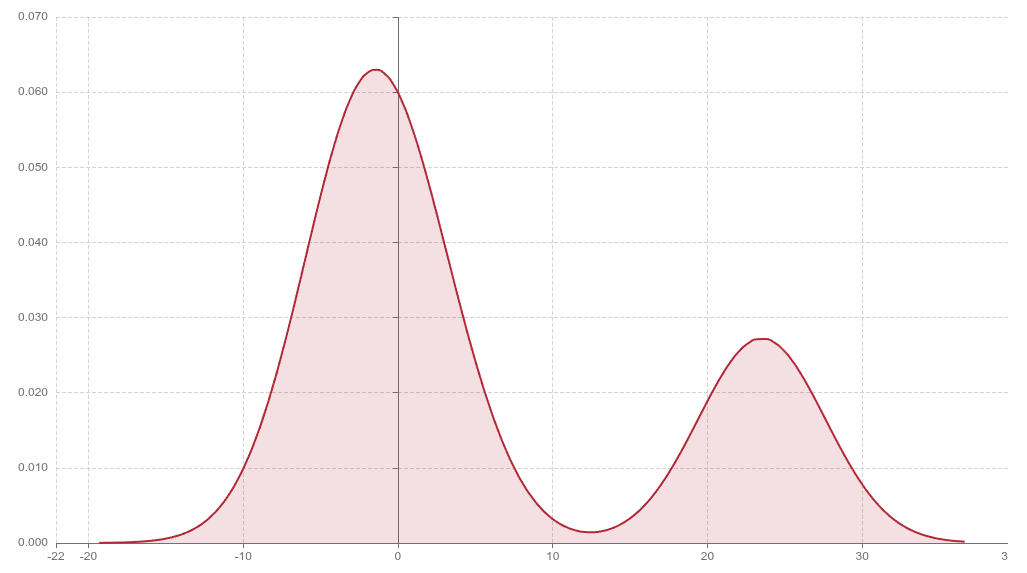
We discovered that two fundamentally different performance profiles were entangled within a single distribution. The policy excelled in close-range scenarios where the ball was positioned near the robot. However, it struggled significantly when the ball was positioned far away or at extreme angles. By isolating these conditions, the picture becomes much clearer (Figure 2).
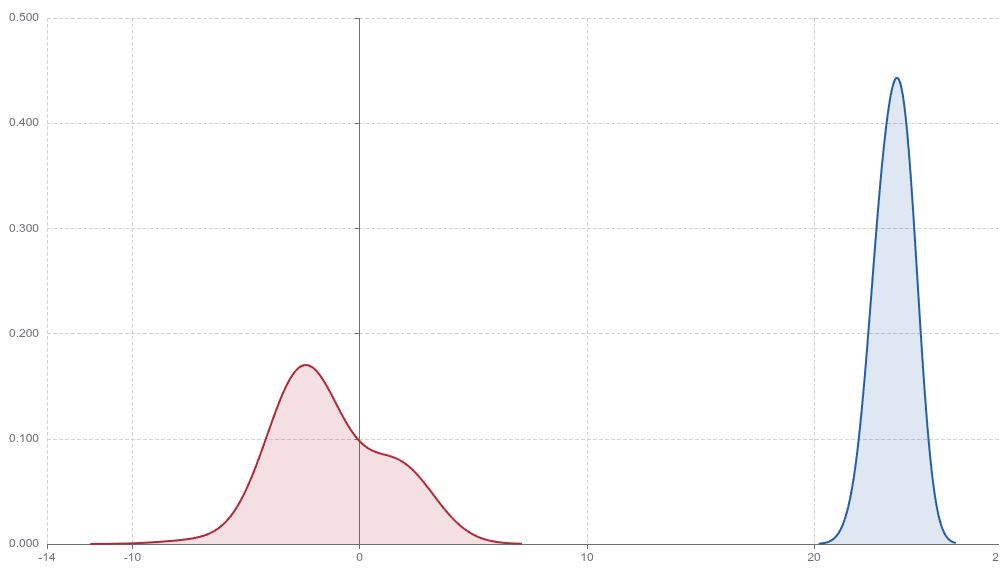
This case illustrates a broader challenge in robotics evaluation: aggregate metrics can obscure important details about what a policy has actually learned. A 28% overall success rate told us very little, but breaking this down revealed strong performance on one class of scenarios and substantially weaker performance on another. This decomposition provides actionable insights into where future training efforts should be concentrated.
Figure 3: Episodes sampled from both the 'good' and 'bad' distributions.
What we’re building now
As part of SAI’s broader mission, our focus is on robotics policy evaluation with an emphasis on understanding where and why policies fail when deployed outside controlled settings. We do this by studying how performance changes when different parts of the system are stressed. This includes:
- Visual perception (blur, lighting, occlusions)
- Language understanding (ambiguous or varied instructions)
- Computation (slower hardware, quantized models)
- Physical execution (actuator noise, calibration drift)
The goal is to make benchmarks more informative for real-world deployment.
Instead of just measuring performance, we characterize behavior under real-world variation. In our new platform you will be able to see where the system is stable, where it’s fragile, and what kinds of failures to expect.
Why this matters
Most discussions of robustness focus on individual components in isolation. A vision model degrades under blur. A language model struggles with ambiguous phrasing. A controller becomes unstable under noise.
Understanding the marginal impact of each component is valuable and a necessary first step. But real robotic systems are composed of interacting parts, which means failures don’t just occur in isolation.
A small visual distortion might be fine on its own. A slightly ambiguous instruction might be fine on its own. But together? The system fails in ways neither perturbation would predict alone.
This blog series is about building a framework that accounts for that.
We’ll start by formalizing what robustness means in a real robotic system. Then we’ll show how to measure it systematically. And finally, we’ll demonstrate how understanding sensitivity profiles leads to more reliable deployment.
Knowing where your system will break is just as valuable as knowing where it works.